本文作者来自于清华大学和上海 AI Lab,通讯作者为清华大学丁宁助理教授和清华大学讲席教授、上海 AI Lab 主任周伯文教授。

论文:https://arxiv.org/abs/2501.18362
代码: https://github.com/TsinghuaC3I/MedXpertQA
榜单:https://medxpertqa.github.io
论文已被 ICML 2025 接收,并且被 DeepMind MedGemma 采用为评估基准。
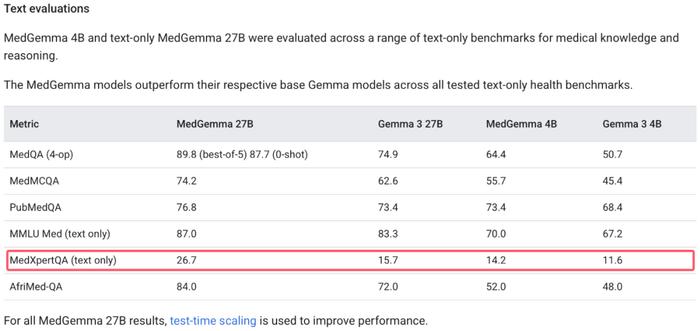
基准地址:https://deepmind.google/models/gemma/medgemma/
为什么我们需要一个新的医学基准?
前沿的 AI 模型距离应用于真实世界的医疗场景还有多远?
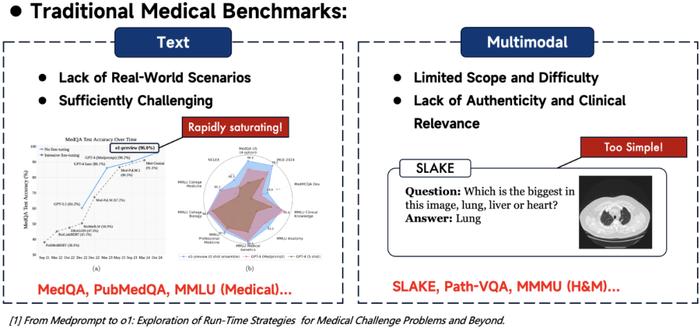
1. 现有基准难度不足:前沿人工智能模型能力的提升,通常依赖于高难度且能够合理评估模型表现的基准的引导与推动。然而,即使是最具代表性的高难度医学基准 MedQA 也正在快速饱和(o1 已经 96 分)-> 现有医学基准已难以有效评估和驱动前沿模型的进一步发展。
2. 现有基准临床相关性不足:医学人工智能的一个核心要求是能够适应真实世界的临床诊断场景。然而,现有的文本医学基准普遍缺乏对真实临床环境的充分覆盖,而以往的多模态医学基准则还停留在自动生成的简单问答对,临床相关性严重不足。
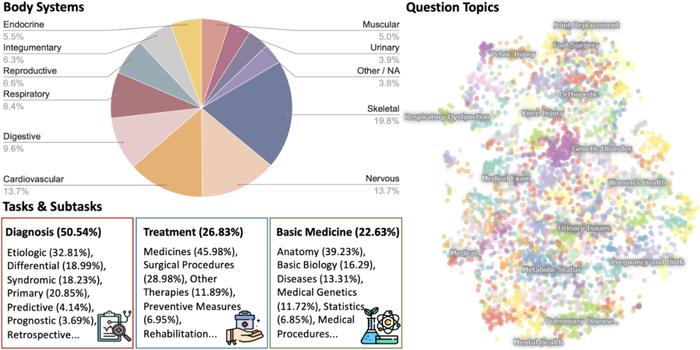
因此,我们提出了 MedXpertQA,包括涵盖 17 个专业和 11 个身体系统的 4,460 个问题。它包括了两个子集,分别是用于文本医学评估的MedXpertQA Text 和用于多模态医学评估的 MedXpertQA MM 。
为什么选 MedXpertQA?
怎么实现高难度和高临床相关性?另外,对于一个医学基准仅有这两点还不够。问题的多样性如何?质量如何?
MedXpertQA 面向上述挑战做出了重大改进:
极具挑战性,有效区分前沿模型:
MedXpertQA 引入了高难度医学考试题目,并进行了严格的筛选和增强,有效解决了现有基准如 MedQA 难度不足的问题;
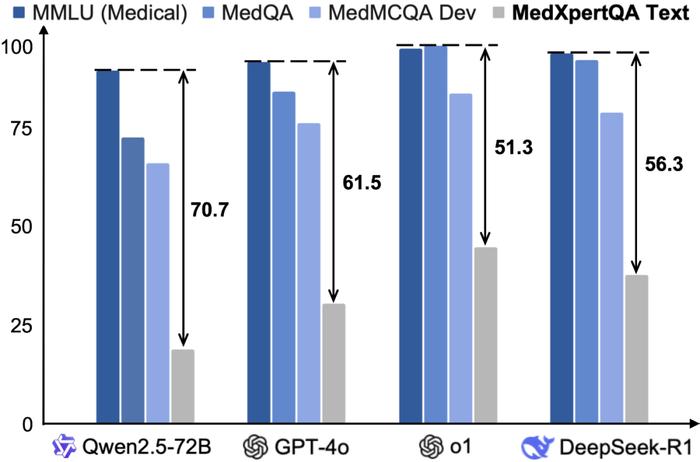
MedXpertQA 是目前最具挑战性的医学多选题(MCQA)评测基准 [1],甚至超越 Human's Last Exam (Medical) [2, 3]。下图展示了前沿模型在各个基准上的表现:
高临床相关性,真实诊断场景:
权威且广泛的数据来源:收集了累计超过 20 个美国医学执照考试的问题,问题均由高水平专家设计,首次引入专科委员会问题,以提高临床相关性和全面性。
2 个美国医师执照考试:USMLE 和 COMLEX
17/25 个美国医学专科委员会下属专科的执照考试
多个考察图像理解的科目考试(欧洲放射学委员会等)
初始收集了 37543 个问题,为 MedQA-USMLE 的 3 倍左右

下一代多模态医学评估:
MedXpertQA 使用真实场景的、专家设计的高难度问题构建多模态(MM)子集,相较传统的多模态医学评估基准做出重大改进;
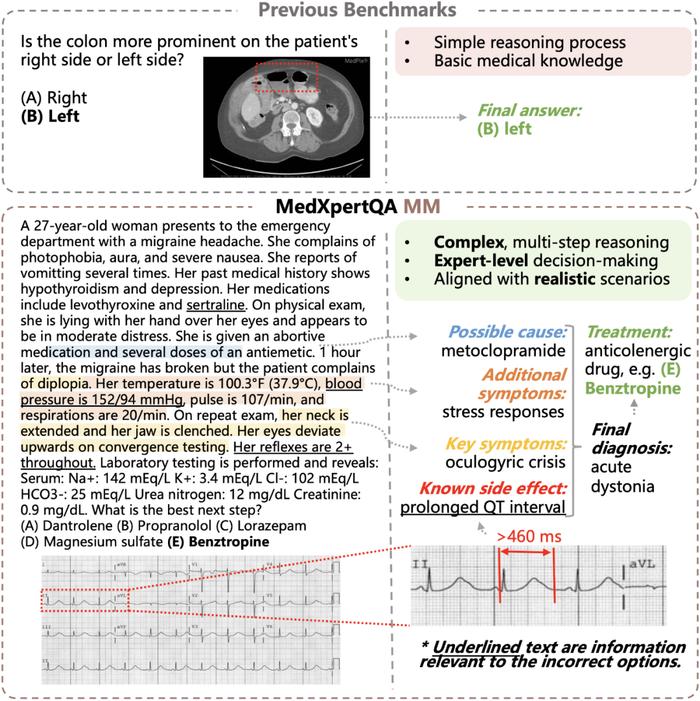
包括多样化的图像和丰富的真实临床信息,考察专家级知识和高级推理能力。而传统医学多模态基准为由图像标题自动生成的简单问答对,下图展示了一个对比:
「全面的」多样性:
医学属性:覆盖了超过 17 个医学专科,覆盖了权威医学教科书中定义的所有身体系统(11 种);
模态:除了放射学,生命体征等医学影像,还引入了医生诊断过程中可能需要的文档,表格等模态信息,完全贴近真实世界的临床场景;
任务:覆盖了真实诊断场景中的大量诊断任务。
极低数据泄露:
我们进行数据合成以减轻数据泄露风险,并开展多轮专家评审以确保准确性和可靠性;
我们进行了数据污染分析,发现经过数据合成后数据泄露的风险进一步降低;
MedXpertQA 是目前数据污染程度最低的医学评估基准 [1],可以极大程度上实现模型能力客观和准确的评估。
面向 o1 类模型的医学推理能力评估:
MedXpertQA 中的大量题目不仅考察医学知识记忆,更要求模型进行复杂推理。例如,部分题目需要模型整合文本与图像中的多重信息线索,排除干扰,形成完整逻辑链以正确解答;
为此,我们根据题目考察的核心能力(Reasoning 或 Understanding),对每个问题进行了标注。大部分题目归属 Reasoning 子集,难点在于医学场景下的复杂推理,尤其适合评估模型的医学推理能力。
MedXpertQA 是怎么构建的?
在数据收集阶段,我们以多样性和临床相关性为核心考量。而在后续的构建阶段,我们主要考虑四大核心原则:挑战性、鲁棒性、未见性、准确性。
数据收集之后,MedXpertQA 的构建经过了过滤、增强和专家审查四个步骤:
挑战性:
三重过滤机制问题筛选:
人类作答分布:利用真实用户回答的对错分布,计算 Brier score 等指标分析问题的难易程度;
专家标注难度:医学专家对问题难度进行分级;
AI 模型测试结果:选取 8 个领先的 AI 模型,完成 14 次独立实验,识别高难度问题。
选项扩充:额外生成干扰的错误项,文本(Text)子集扩充至 10 个选项,多模态(MM)子集扩充至 5 个选项。
鲁棒性:
相似问题过滤:从文本编辑距离和语义层面识别并移除高度相似的问题,降低模型识别 shortcut 进而 hacking 的风险。
未见性:
问题改写:为了降低数据泄漏风险,客观评测模型能力,我们对每道题的表述进行了彻底的改写。改写后的句子内容保持信息完整,但形式上有明显差异,有助于客观评估模型的能力;
准确性:
多轮专家审查:
持有医学执照的专家组成审查组,对完整题库进行了多轮审查,修正数据增强过程中引入的错误或原始数据错误,检查并修复信息缺失、不一致、叙述混乱等问题;
发现并修改近千个问题,专家对问题进行了细致的统计,错误归类与人工纠错,保证最终基准的准确性。
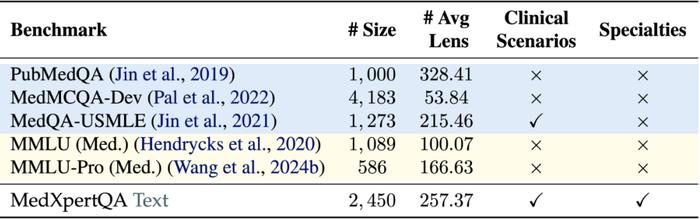
经过严格筛选与审查,MedXpertQA 最终保留了原始题库约 12% 的题目,共计 4,460 题,体现了对质量而非数量的优先考量。下表展示了和现存基准的对比,可以看到 MedXpertQA 展现出了巨大的优势:

前沿模型表现如何?
我们在 MedXpertQA 上评测了领先的多模态及纯文本模型,包括 o3、DeepSeek-R1 等推理模型,更多分数细节可以参考 Leaderboard:https://medxpertqa.github.io。
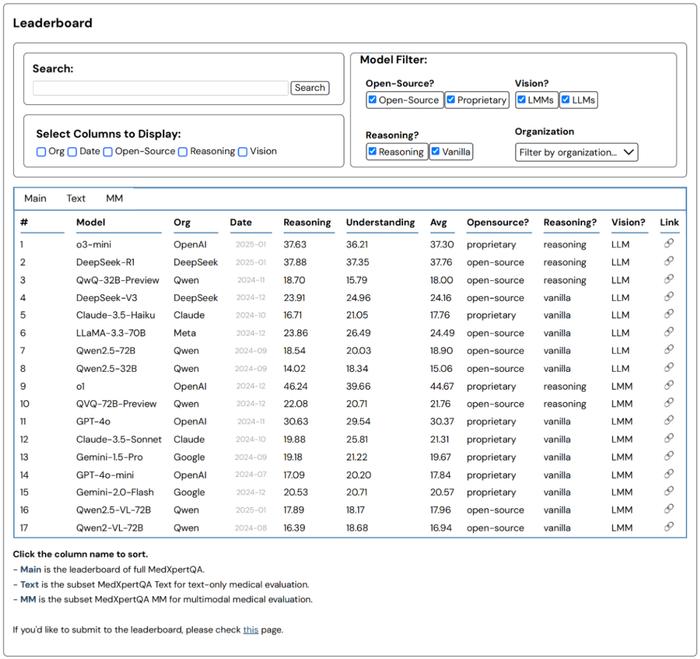
模型表现差距显著: 多模态模型中,o1 得分最高,但在两个子集上的总体准确率未超过 50%,表明前沿模型在医学领域仍有较大提升空间。在 Text 子集上,DeepSeek-R1 是最优开源模型,但与 o1 存在一定差距;
人类性能基线:我们根据构建基准时收集的每个问题的作答数据计算了人类医学生在原始试题上的准确率,进而构建了一个人类性能的极限,其中每个问题的作答数量最高达到 23 万个,因此具有高度代表性;
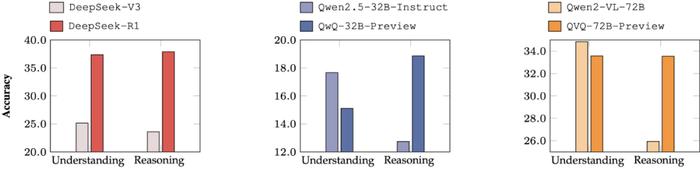
推理增强模型在 Reasoning 子集优势明显: 对比三组基座模型及其推理模型版本得知,增强模型在 Reasoning 子集上展现出显著且稳定的性能提升,而在 Understanding 子集上则没有这一趋势,这表明 Reasoning 子集尤其适合 o1 类模型评估;
错误分析揭示推理密集特性: 我们利用 LLM 对 GPT-4o 的完整回复进行了错误类型标注,发现推理过程错误和图像理解错误最为常见,纯粹的医学知识性错误则相对较少。
以上结果从多角度印证了 MedXpertQA 的价值,尤其凸显了 Reasoning 子集的必要性。
总结
MedXpertQA,一个高难度的、高临床相关性的、全面的医学基准、面向专家级医学知识和高级推理能力的评估。当前研究已广泛体现出推理能力对医学 AI 模型的重要性。
我们进一步提出:医学作为一个复杂、丰富且至关重要的领域,有潜力成为评估模型推理能力的新场景,从而拓宽当前以数学和编程为主的评测范式。我们期待 MedXpertQA 能成为推动专业医学模型与通用推理模型共同发展的重要资源。
参考文献
[1] Tang, Xiangru, et al. "Medagentsbench: Benchmarking thinking models and agent frameworks for complex medical reasoning." arXiv preprint arXiv:2503.07459 (2025).
[2] Wu, Juncheng, et al. "Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs." arXiv preprint arXiv:2504.00993 (2025).
[3] Phan, Long, et al. "Humanity's last exam." arXiv preprint arXiv:2501.14249 (2025).